视频结构化
一、示例简介
1. 应用场景
目前视频结构化系统应用广泛,可用在交通卡口、电警系统、智慧城市等多个场景中。
2. 实现功能
为给客户提供定制化的整体解决方案,同时为展示星空体育智能加速卡(MLU)的功能和性能,实现了一套包括视频解码、目标检测、目标追踪、车辆/行人属性识别、车牌识别等典型功能的视频结构化解决方案。
二、方案优势
1. 使用星空体育智能处理卡,为端、云侧推理提供的强大运算能力支撑,并具备视频解码功能。
2. 基于cnstream开源框架,以模块的方式组织功能,可以根据具体场景方便地增加或替换模块,具有很高的扩展性。
3. 根据星空体育硬件进行优化,通过多batch等方式,充分利用多个MLU core进行平行处理。
4. 直接加载星空体育离线模型,脱离深度学习框架,直接调用星空体育运行时库(CNRT),具有很高的执行效率。
三、适配规格
1. 硬件平台
星空体育MLU220系列智能处理卡
MLU220是一款专门用于边缘计算应用场景的人工智能加速卡。产品集成4核ARM CORTEX A55,LPDDR4x内存及丰富的外围接口。用户既可以使用MLU220作为AI加速协处理器,也可以使用其实现SOC方案。

星空体育MLU270系列智能处理卡
星空体育 MLU270采用星空体育MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。
MLU270集成了星空体育在处理器架构领域的一系列创新性技术,处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。

|
最低配置 |
8张MLU270对应总共不少于16个CPU核心 |
不低于2倍加速卡缓存容量的系统内存,256GB |
|
建议配置 |
8张MLU270对应总共不少于32个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,384GB |
|
4张MLU270对应总共不少于16个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,192GB |
案例展示
|
服务器厂商 |
型号 |
高度 |
CPU平台 |
MLU板卡 |
插卡数 |
|
Inspur |
NF5468M5 |
4U |
2* Intel Xeon Scalable Processor |
MLU270-X5K |
8 |
|
NF2180M3 |
2U |
FT2000plus |
MLU270-A4K |
4 |
|
|
GreatWall |
DF720 |
2U |
FT2000plus |
MLU270-A4K |
2 |
2. 软件环境
依赖星空体育驱动(Cambricon Driver),星空体育软件(Cambricon Neuware)中的编解码库(CNCodec)、运行时库(CNRT)、CNDev、CNDrv、CNML、CNPlugin等。
四、功能介绍
视频结构化系统由采集系统、结构化信息分析系统组成,如下图所示:
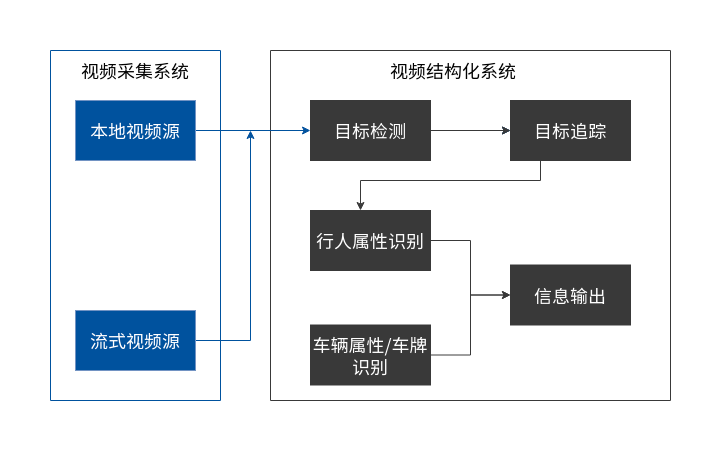
采集系统可以接入RTSP流、RTMP流或者本地视频,支持多路接入。
视频结构化分析系统是整个系统的核心部分,负责对采集的视频流进行一些列的流水线操作,最终分析出来视频里面的行人属性、车辆属性、车牌信息等。
视频结构化分析系统包括:目标检测、目标追踪、行人属性识别、车辆属性识别、车牌识别等子模块。
五、实现方案
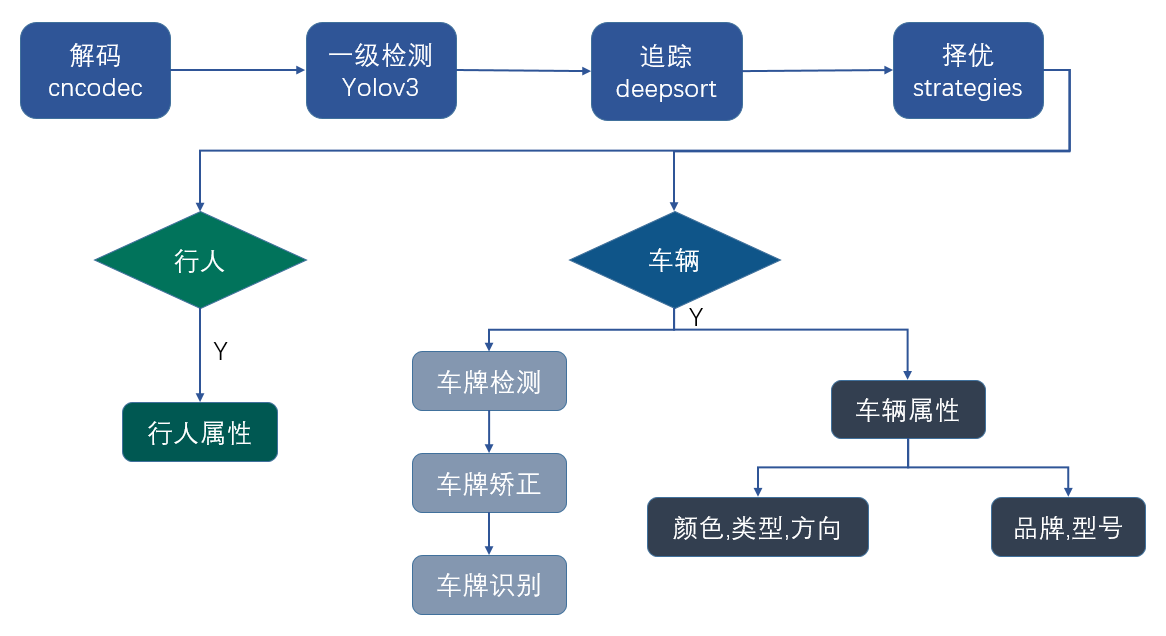
1. 流程图
视频结构化分析系统采用cnstream框架进行开发,通过搭建多个插件,组合成流水线来完成视频结构化的整体功能。
每一个环节由一个插件来完成,插件是以多线程的方式并行执行,插件之间的数据传输通过阻塞式的消息队列实现。
视频结构化业务流程图如下:
2. 解释说明
整个流程包括以下环节:解码、检测、追踪、选优、行人或车辆属性分析、输出等。
1)解码
系统的首个插件是解码插件。解码插件需要能够解析RTSP/RTMP视频流,本地各种编码格式的视频文件以及JPEG图像。实际使用的解码模块可使用CPU来软解码,也可采用MLU硬件解码器模块完成解码。
考虑到CPU资源比较宝贵(后续很多插件都会大量使用CPU资源),所以一般情况下,采用cnstream的decoder模块实现MLU解码功能。
解码的方式有两种,与前处理操作关系紧密。一种是CPU做前处理,另一种是在MLU上做前处理。
2)CPU前处理
在MLU端解码之后,把YUV数据拷回到主机(CPU)端,然后用CPU做前处理,主要包括颜色转换、resize、减均值除方差等。之后再把输入拷到MLU端进行后续的推理操作。如下图所示。
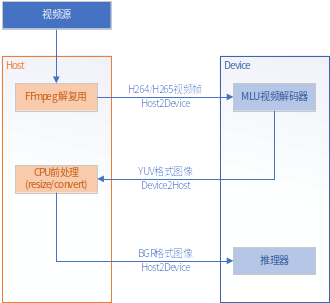
该方案通用性比较好,可适合于各个框架生成的离线模型。但是性能较差,需要两次拷贝操作,而且占用PCIE带宽比较严重。因为前处理后的数据是RGB格式的,数据量比较大,是YUV格式的2倍,所以此处很容易成为整个系统的瓶颈。
3)MLU前处理
MLU前处理指的是解码后输出在MLU内存的YUV数据不再拷回主机端,而利用MLU Resize/Convert算子在MLU上直接把解码后的YUV数据转换成后续推理插件离线模型所需的格式和尺寸。
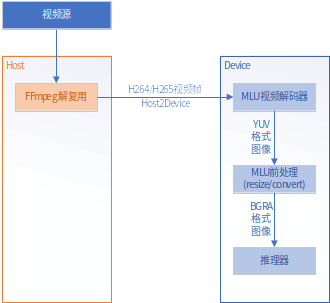
该操作可以实现解码后数据的零拷贝,另有一个优势是当推理插件需要攒batch处理数据时,RC算子能协助把处理过的数据摆放在各batch对应的地址上。
MLU前处理带来的资源开销明显少于CPU前处理,因此对于MLU板卡的视频结构化解决方案,应尽量选择MLU前处理。
4)Scaler前处理
MLU220系列芯片内部集成了支持裁剪、缩放、颜色格式转换的硬件Scaler模块。对于大部分只需进行减均值、除方差前处理的网络模型使用Scaler模块来完成对输入图像的裁剪缩放等操作,能进一步降低由上述RC算子前处理所带来的MLU算力开销。
5)目标检测
在模型评估阶段,选择了性能和精度相对均衡的YOLOv3网络,该网络由自采数据集训练后减少输出分类到两类,分别是行人和车辆。
因为部署模型是采用离线的方式。在尝试各种可用尺寸并测出精度数据后,对比选择了精度最佳的608x608作为模型的输入尺寸。
处理一路视频流时,时延在50ms左右。但在多路的情况下,由于MLU核和内存通道都存在竞争,路数越多,竞争导致时延越来越长,进而导致吞吐(fps)下降。因此需要考虑对检测插件进行性能优化。优化的最有效的手段,是充分利用空闲的核,进行并行计算。
由于视频流是连续的,因此对于某一路视频流,可通过攒batch的方式进行并行推理。例如设置batch为4,一次推理,同时在4个MLU核上操作这4帧图像,相当于同一时刻每个核处理一帧图像。那么检测插件就在攒够4帧图片时,才送去做推理计算。这样充分利用了MLU多核的优势来提高吞吐。
6)追踪
追踪模块采用星空体育自研easydk中的feature match方式进行追踪,由MLU通过feature extractor模型提取目标特征提供给feature match模块,经过卡尔曼滤波,匈牙利匹配等方式,实现目标追踪,并对追踪成功的目标分配track_id。
追踪插件在目标较多的情况下同样会遇到吞吐瓶颈的问题,因此采用了与检测器一样的攒batch方式提高fps,目前设置为4 batch。
7)择优
择优插件是在视频流的多帧数据中针对每一个目标筛选出一个相对较好的图像来进行二级结构化属性分析。视频经过一级结构化目标检测器后,分析出的目标质量参差不齐,如果全部做二级结构化属性分析可能在浪费了算力的同时还得不到很好的效果,因此需要一种策略来筛选出一个相对较好的图像来做结构化分析。
择优插件的计算过程依赖追踪插件的结果,因为择优的前提是针对同一个目标(相同track id)而进行的。所以追踪的结果也一定程度影响择优的准确率。
择优插件可以针对一级结构化输出结果的某一些类别进行择优,择优过程支持多个“与”关系的策略条件,包括目标大小、目标变化趋势、目标位置、目标框是否靠边等等。只有目标满足所有策略条件后,才会提供给后续的二级结构化插件进行属性分析。
为了可以更准确的识别车辆属性和车牌信息,需要对针对不同的场景来设置一些筛选策略。车辆在视频上的大小很大程度上决定了属性分析的结果,如果目标太小的,很难获取到正确的车牌,因此需要对目标大小的进行过滤,根据用户设置的阈值来决定是否去做属性和车牌分析。
为了减小属性分析的次数,只有当目标大小处于变大趋势,且变化趋势超过设置的阈值时,才会再次进行分析,这样可以保证不会一直分析同一个静止的目标。
8)行人属性识别
行人属性网络采用AWMT caffe框架模型,其backbone是ResNet50分类网络,其支持多标签的分类。通过PA-100K和自采数据集叠加训练后,平均精度为76.32,各个属性的精度数据如下表所示:
|
属性 |
精度 |
属性 |
精度 |
|
Sex |
86.80 |
Hat |
61.46 |
|
Age<16 |
66.40 |
Glasses |
73.39 |
|
Age10~60 |
64.17 |
Handbag |
71.68 |
|
Age>60 |
54.29 |
Knapsack |
73.44 |
|
Front |
87.30 |
Shouldbag |
68.75 |
|
Side |
84.39 |
LongSleeve |
88.81 |
|
Back |
91.39 |
|
|
9)车辆属性识别
车辆属性识别网络采用backbone为GoogleNet的网络,其一模型经由compcars数据集训练用于识别车辆品牌系列,另一模型由自采数据集进行颜色/种类/视角的训练。经过测试得到精度结果分别如下:
|
属性 |
精度(Top1/Top5) |
属性 |
精度(Top1/Top5) |
|
Models |
86.2/96.6 |
Type |
94.8/99.8 |
|
Color |
92.3/99.9 |
Side |
94.4/99.9 |
10)车牌识别
车牌识别包含了3个网络,分别用于车牌框检测、车牌仿射变换、车牌识别。该插件在CCPD数据集上测试的精度为76.88%.
11)结构化视频输出
为了显示结构化目标检测和追踪的效果,可以为每一路创建一个RTSP 串流服务,用来显示每路的检测和追踪效果,该功能可通过配置文件选择是否打开。
串流输出功能在整个解决方案中是以一个插件的形式加入到流水线中的。这个插件支持FFmpeg软件编码和MLU硬件编码,还可选择重采样视频帧是否按原始视频帧率输出结构化视频。
12)结构化信息输出
为了与其他功能模块对接,本方案可以把视频结构化的结果以各种方式发送到外部功能模块中去。输出的内容可根据实际需要添加或修改。常用的字段包括:摄像头信息、帧号、行人或车辆结构化信息。
行人结构化信息一般包含:
-
Gender 性别
-
Age 年龄
-
HandBag 是否拎包
-
Knapsack 是否背包
-
ShoulderBag 是否背肩包
-
Orientation 朝向(前、后、侧)
-
Glasses 是否戴眼镜
-
Hat 是否带帽子
车辆结构化信息一般包含:
-
Brand 品牌,例如:Audi
-
Series 车款,例如:Q5
-
Color 颜色,例如:White
-
Side 视角,例如:Front
-
Type 类型,例如:SUV
结构化信息输出方式可以根据实际需要进行选择。比如通过TCP消息或者消息队列中间件等。
六、效果展示
编译与运行
MLU220平台
编译
cd ${VS_DIR}
mkdir build
cmake .. –DMLU=MLU220
make
运行
运行脚本:${VS_DIR}/app/iva_vs/run.sh
配置文件:
${VS_DIR}/app/iva_vs/config_220.json
cd ${VS_DIR}/app/iva_vs
./run.sh 220
MLU270平台
编译
cd ${VS_DIR}
mkdir build
cmake ..
make
运行
运行脚本:${VS_DIR}/app/iva_vs/run.sh
配置文件:
${VS_DIR}/app/iva_vs/config_270.json
cd ${VS_DIR}/app/iva_vs
./run.sh
演示效果
车辆属性和车牌检测识别的效果展示:

七、相关资源
将在GitHub(https://github.com/Cambricon)上开源,感谢您的关注。