视频转码
一、示例简介
1. 应用场景
传统视频转码技术主要应用领域是数字电视广播和数字媒体前端处; 互联网时代中,视频娱乐市场以内容为王,能够实时转换任意格式的视频内容是未来市场发展的一个核心趋势。海量的视频数据内容需要海量的计算能力,CPU计算资源宝贵,继续使用CPU进行视频处理操作不但难以满足市场需求,甚至逐渐暴露出低效率和高成本的弊端,所以用硬件实现编解码、转码等是非常必要的。
2. 实现方案
为了适应市场的各方面需求,以及为客户提供便捷易上手的解决方案,同时为展示星空体育智能加速卡的功能和性能,实现了三种视频转码解决方案。
二、方案优势
1. 使用星空体育智能处理卡,为端、云侧推理提供的强大运算能力支撑,并具备视频解码功能。
2. 基于星空体育硬件加速编解码SDK(cncodec)以第三方库的方式进行开发,可以根据具体场景方便地调节与选择,具有很高的扩展性。
3. 直接调用星空体育运行时库(CNRT),具有很高的执行效率。
4. 可与星空体育AI平台同时开发,实现视频转码和AI的高度结合与集成。
三、适配规格
1. 硬件平台
星空体育MLU270系列智能处理卡
星空体育 MLU270采用星空体育MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。
MLU270集成了星空体育在处理器架构领域的一系列创新性技术,处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。
|
最低配置 |
8张MLU270对应总共不少于16个CPU核心 |
不低于2倍加速卡缓存容量的系统内存,256GB |
|
建议配置 |
8张MLU270对应总共不少于32个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,384GB |
|
4张MLU270对应总共不少于16个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,192GB |
案例展示
|
服务器厂商 |
型号 |
高度 |
CPU平台 |
MLU板卡 |
插卡数 |
|
Inspur |
NF5468M5 |
4U |
2* Intel Xeon Scalable Processor |
MLU270-X5K |
8 |
|
NF2180M3 |
2U |
FT2000plus |
MLU270-A4K |
4 |
|
|
GreatWall |
DF720 |
2U |
FT2000plus |
MLU270-A4K |
2 |
2. 软件环境
依赖星空体育驱动(Cambricon Driver),星空体育软件(Cambricon Neuware)中的编解码库(CNCodec)、运行时库CNRT、CNDev和CNDrv等。
四、功能介绍
视频转码的系统用例图,如下图所示:
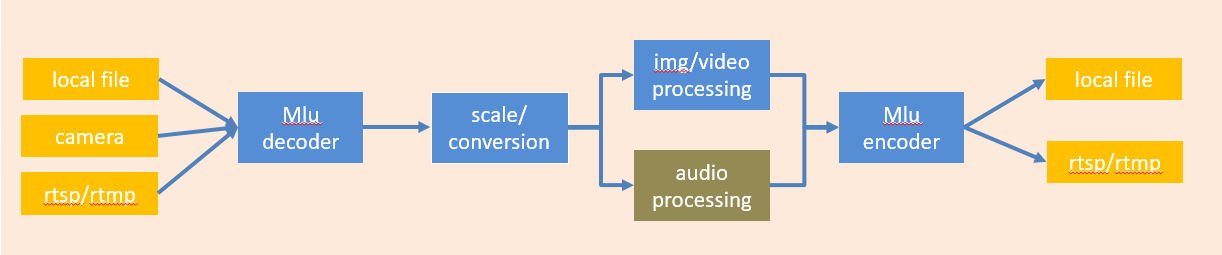
通过系统用例图可发现本系统的主要实现了如下功能:
-
将视频源数据进行硬件解码;
-
cvt/scale/AI inference;
-
将视频源数据进行硬件编码
五、实现方案
转码一共有三种方案:
(1)基于FFMpeg-MLU的转码方案;
(2)基于CNStream的转码方案;
(3)基于CNCodec的转码库;
基于CNStream的转码方案主要是CNStream SDK实现转码的操作,具体实现可参考视频结构化中的实现方案,这里不详细叙述;
基于CNCodec的转码库主要是基于CNCodec SDK的原生接口进行实现,需要对CNCodec的具体接口以及实现原理较熟悉,这里也不再详细叙述;
基于FFMpeg-MLU的转码方案主要是将CNCodec SDK集成到原生开源的FFMpeg中,基于原生FFMpeg丰富的生态及便捷的使用接口,但是底层基于MLU硬件实现。这里主要介绍FFMpeg-MLU转码方案。
FFMpeg-MLU优点:
-
FFMpeg是业界使用最广泛的转码平台,无需改变现有的工作流;
-
使用解码返回Host的架构,可以广泛使用当前已经存在的filter;
-
广泛的demo程序可以使用,方便验证底层硬件;
-
可使用FFmpeg中的filter进行端对端1:N编码或1:N转码视频硬件加速通道;
-
可直接输出YUV,与星空体育AI能力无缝结合,非常容易集成以下增强功能:
-
视频缩放,旋转,色彩变换
-
服务器端广告插入
-
视频水印,裁剪
-
视频去隔行
-
视频拼接
-
流媒体应用开发
-
其他图像视频增强应用
-
1. 转码框架一:
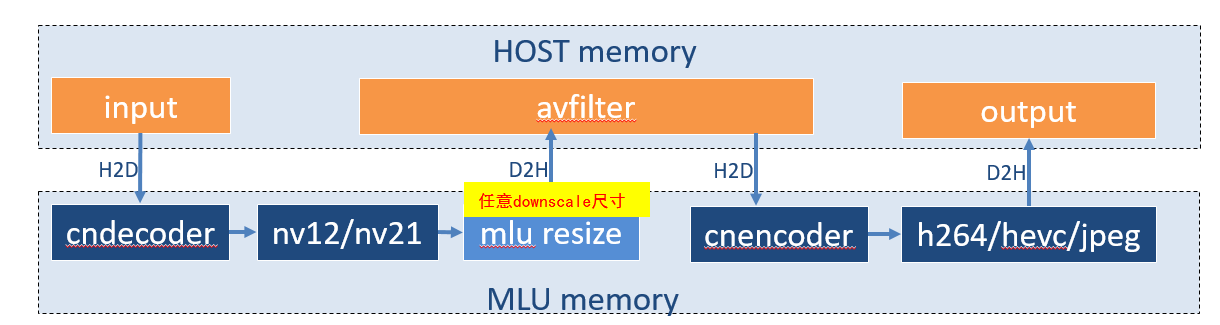
使用硬件解码器与编码器,在解码器与编码器之间,直接连接一个scale resize 算子,算子直接与解码器绑定,算子直接输出到目标尺寸,无需再使用cpu resize操作,然后再做编码操作。
2. 转码框架二:
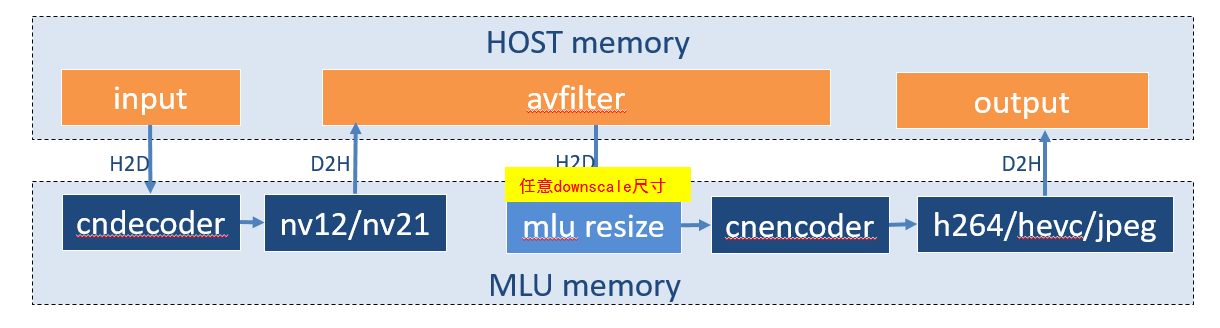
使用硬件解码器与编码器,在解码器与编码器之间,直接连接一个scale resize 算子,算子直接与编码器绑定,算子直接输出到目标尺寸,然后直接做编码操作。
3. 转码框架三:
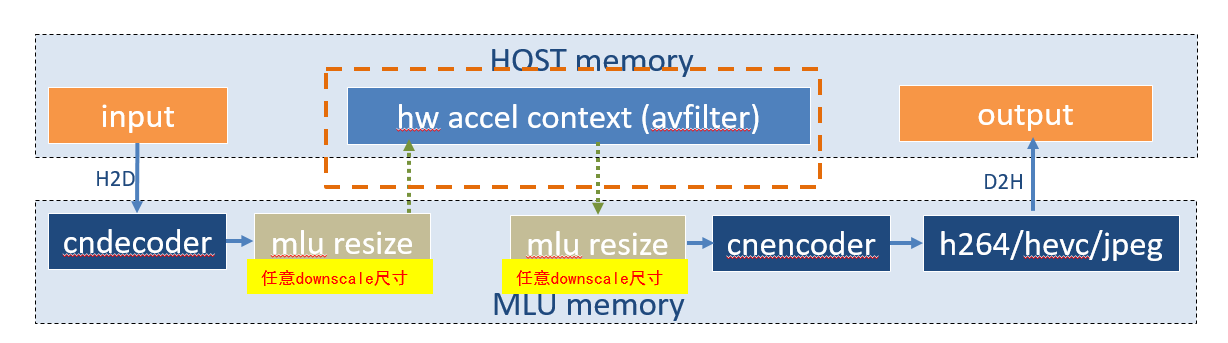
使用硬件解码器与编码器,在解码器与编码器之间,直接连接一个scale resize 算子,算子作为独立的filter模块,算子直接输出到目标尺寸,然后直接做编码操作。
4. 转码框架四(与AI联用):

前后处理以filter的形式集成;
推理以filter的形式集成,filter进行离线与在线的推理;
可使用原生命令行操作,也可以基于API开发;
需要丰富的前后处理hwfilter。
六、效果展示
1. 实现1920x1080的视频转为352x288:
通过命令行实现:
./ffmpeg -re -y -c:v h264_mludec -i res_4.h264 -s 352x288 -c:v h264_mluenc -b:v 32k -rc cbr -qmin 1 -qmax 39 -bf 4 -g 50 cif.h264
1920x1080 --> 352x288
2. 实现多路视频拼接成一路视频:
通过命令行实现:
./ffmpeg -y -c:v h264_mludec -i <input_1> -i <input_2> -i <input_3> -i <input_4> -filter_complex "nullsrc=/Other/developer/index/resources/exadetails/classid/15/id/size=640x480/index.html [base]; [0:v] setpts=PTS-STARTPTS,scale=320x240 [upperleft]; [1:v] setpts=PTS-STARTPTS,scale=320x240 [upperright]; [2:v] setpts=PTS-STARTPTS, scale=320x240 [lowerleft]; [3:v] setpts=PTS-STARTPTS, scale=320x240 [lowerright]; [base][upperleft] overlay=shortest=1[tmp1]; [tmp1][upperright] overlay=shortest=1:x=320 [tmp2]; [tmp2][lowerleft] overlay=shortest=1:y=240 [tmp3]; [tmp3][lowerright] overlay=shortest=1:x=320:y=240" -c:v h264_mluenc out.mp4
3. 实现rtsp拉流/转码/rtmp推流:
通过命令行实现:
./ffmpeg -re -y -stimeout 5000000 -rtsp_transport tcp -c:v h264_mludec -i rtsp://10.100.9.75:554/jellyfish-3-mbps-hd-h264.mkv -s 253x288 -vcodec copy -acodec copy -c:v h264_mluenc -f flv -y rtmp://10.100.8.47:554/live/test
七、相关资源
您可以访问Github上的开源仓库:https://github.com/Cambricon/ffmpeg-mlu