

一、内容和目标
1. 实验内容
-
本实验主要介绍基于星空体育 MLU370,使用星空体育高性能算子,完成Transformer的翻译任务。
-
基于星空体育 MLU370 高性能大算子,您可以读取数据集,对相应的统计结果进行评估。
2. 实验目标
-
掌握使用星空体育 MLU370 大算子进行模型推理的基本方法。
-
理解 Transformer 模型的整体网络结构及其开发调试细节。
二、前置知识
了解星空体育软硬件平台:
-
硬件:星空体育 MLU370 AI 计算卡
-
框架:PyTorch 1.6 、CNNL
-
系统环境:星空体育云平台
三、网络结构
Google于2017年6月提出了Transformer模型。Transformer 在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。
其网络结构如下图所示:
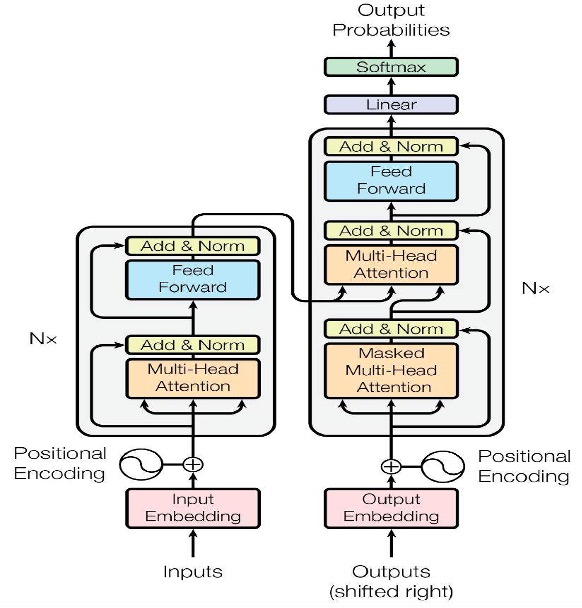
其中:
【Attention】
Attention 的主要作用是把“注意力”放在一部分输入上。它主要涉及到3个概念:Query、Key 和 Value。在增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始 Value,Attention 机制将目标字作为 Query、其上下文的各个字作为Key,并将 Query 与各个 Key 的相似性作为加权系数,把上下文各个字的 Value 融入目标字的原始 Value 中。
对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
为了增强 Attention 的多样性,文章作者进一步利用不同的 Self-Attention 模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量,这就组成了Multi-head Self-Attention。
【Transformer Encoder】
Transformer Encoder有两个子层,一个是multi-head attention层,另一个是feed forward层,简单的全连接网络。Transformer Encoder 在 Multi-head Self-Attention 之上又添加了三种关键操作:
-
残差连接(ResidualConnection)
-
Layer Normalization
-
线性转换
-
Transformer Decoder
Transformer Decoder中有三个子层,其中两个multi-head attention层,这个attention层并不是 self-attention,而是encoder-decoder attention,用来学习源句与目标句之间的关系。对于这个Attention,query代表decoder上一步的输出,key和value是来自encoder的输出。最后再经过一个与编码部分类似的feed forward层,就可以得到decoder的输出了。
四、模型推理
模型推理整体流程如下图所示:
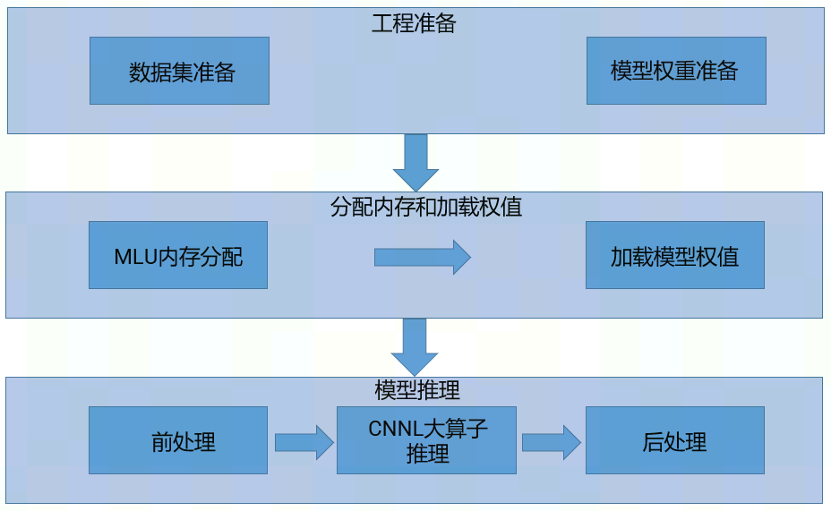
STEP 1. 工程准备
-
预训练模型准备:本实验的模型是星空体育自己训练的模型,并将其放置于
/workspace/model目录下。 -
搭建环境:
pip install -r requirements.txt。
STEP 2. 工程运行
-
构造我们提供的 estimator 对象。
-
load_weight接口完成 Transformer 模型在 MLU内存上的分配,然后加载模型到MLU上。 -
调用
input_fn编码生成输入数据。 -
调用predict 进行推理。
-
调用
_trim_and_decode对结果进行后处理。
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo